
AI Skill 也会"退休",企业到底怎么管?
我经常打一个比方:
普通文档像便利贴,Skill 更像企业里的微服务。
便利贴写完贴墙上就完事了,没人会问它"什么时候该被替换"、"调用方有没有迁移"、"谁在维护它"。
但微服务不一样。它有版本,有 owner,有 SLA,有上线流程,有废弃流程。
企业级 Skill 也应该这么对待。
我研究 Hermes 的过程中,发现一个有意思的现象:很多团队会很认真地写 Skill,但写完之后就没人管了。半年之后,Hub 里堆着上百个 Skill,没人知道哪些还在用、哪些已经过期、哪些其实重复了。
这就是缺乏生命周期治理的典型后果。
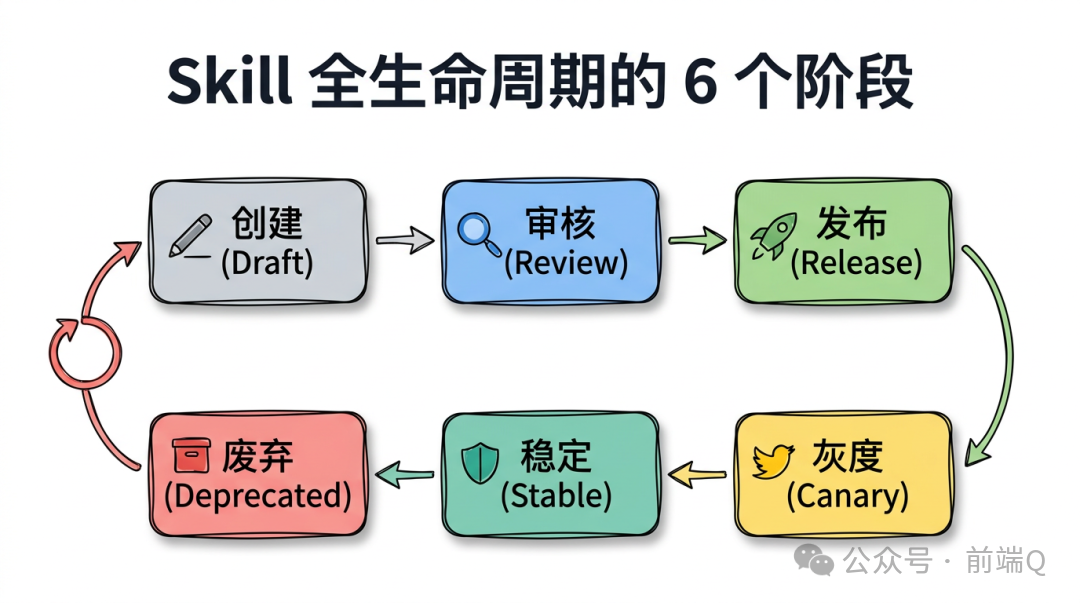
这一篇我把企业 Skill 的全生命周期讲透,分成 6 个阶段:
创建(Creation)
审核(Review)
发布(Release)
灰度(Canary)
运行(Live)
废弃(Deprecation)
每个阶段都有自己关心的事,规则不能混。
阶段 1:创建(Creation)
Skill 生命周期的起点,是有人提出"我要写一个 Skill"。
这一步的关键不是技术,而是 判断是否真的需要新 Skill。
我见过太多企业 Skill Hub 进入"垃圾仓库"状态:每个人都在写新的,没人 review 是不是已经有同名同义的,最后出现 5 个差不多的"代码评审 Skill",互相不知道对方存在。
所以创建阶段第一件事是 重复性检查:
这个检查可以自动化:每次提交新 Skill,先做语义搜索,把高相似度的已有 Skill 列出来。
如果重复性高,引导作者:
第二件事是 场景描述模板。
要求新 Skill 的发起人填一份场景描述,至少包含:
没有这份提案,不接受新建 Skill。
这个机制看起来挺重,但实际效果是:50% 的新 Skill 提案在这一步会被打回(因为已经有了)。
阻止重复,是 Hub 健康的最基础动作。
阶段 2:审核(Review)
新 Skill 写完之后进入审核。
这一步不是只看代码,而是看四个维度:
业务对齐审核
由 Skill 的领域专家来看:
业务对齐审核必须由业务方做,平台团队代替不了。
工程质量审核
由平台团队做:
安全合规审核
特别针对涉及敏感操作的 Skill:
如果命中以上任一项,必须额外走安全团队审核。
性能与成本审核
很多团队忽略这一步:
我见过一个 Skill 因为写得太啰嗦,每次调用花 2 万 Token,上线之后一周烧掉团队半年预算。
性能与成本审核能帮你避免这种事。
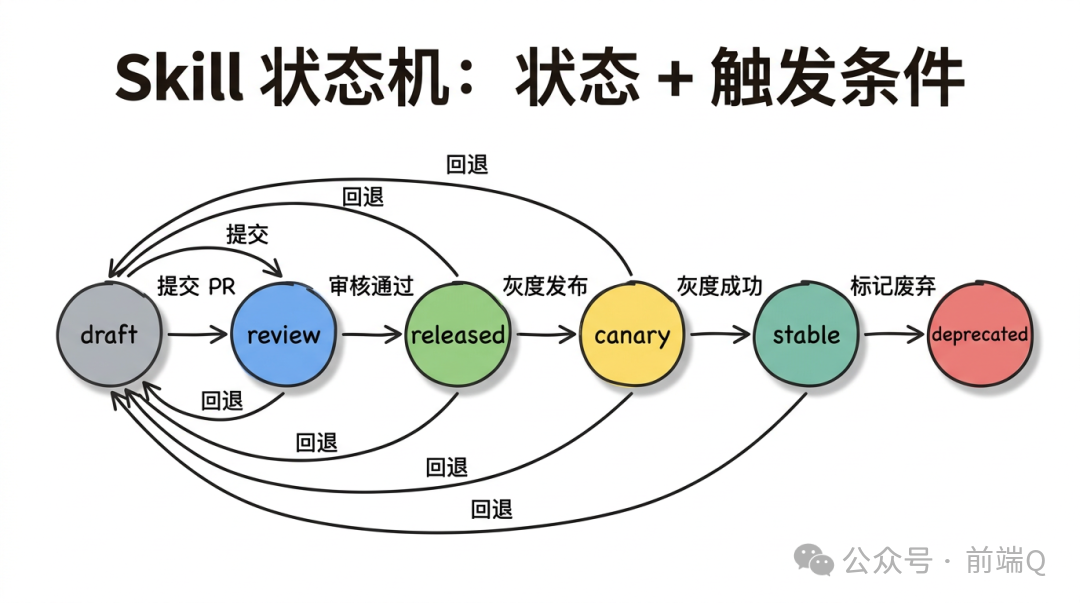
阶段 3:发布(Release)
审核通过后进入发布。
发布不是直接全量上线,而是分四档:
| 档位 | 含义 | 谁能用 |
|---|---|---|
| internal | 团队内部使用 | Skill owner 团队 |
| preview | 预览版 | 已订阅 preview 的团队 |
| canary | 灰度 | 抽样调用方 |
| stable | 稳定 | 全量 |
不同档位适合不同情况:
每一档之间的迁移都需要数据支持。
我建议这样的迁移规则:
这套数据化迁移规则的好处是:升档变成"客观满足条件",而不是"老板拍脑袋"。
阶段 4:灰度(Canary)
灰度是企业级 Skill 上线的核心动作。
很多团队做"灰度"只是把 feature flag 拨一半,根本没真正监控数据。
合格的灰度至少要做四件事:
1. 选灰度群体
不能随机选。要选 能反馈的群体。
比如:
2. 监控关键指标
灰度期间必须监控:
任何指标显著恶化,自动暂停灰度。
3. 设定明确的 abort 触发条件
事先约定哪些情况要立刻 abort:
碰到任一触发条件,自动回滚到上一稳定版本。
不要等老板拍板。等老板拍板就晚了。
4. 灰度期满判定
灰度期间表现稳定 ≥ 7 天,才能升档。
判定要严格:
全部 ✅ 才能升档。
阶段 5:运行(Live)
Skill 上线之后的运行阶段,不是"啥都不用管"。
这一段最容易被忽略,但风险最大,因为:
如果不持续监控,一个月后这个 Skill 可能已经悄悄退化了。
运行阶段必须持续做的事:
持续监控
监控指标基本和灰度期一样,但是 常驻:
异常告警
任何指标显著漂移,自动告警给 owner。
我经验里特别要盯三个:
步骤数无故变多:往往是 Skill 开始绕路
Token 消耗突然上涨:往往是模型行为变了
同一类失败模式集中出现:往往是某个上游变了
定期复盘
每月或每季度,对每个 Skill 做一次系统复盘:
复盘结果要落到行动项:
阶段 6:废弃(Deprecation)
废弃是最容易被偷懒的阶段。
很多团队的"废弃"就是把 Skill 删了,然后调用方一脸懵:突然某天 Agent 报错,查半天才发现 Skill 没了。
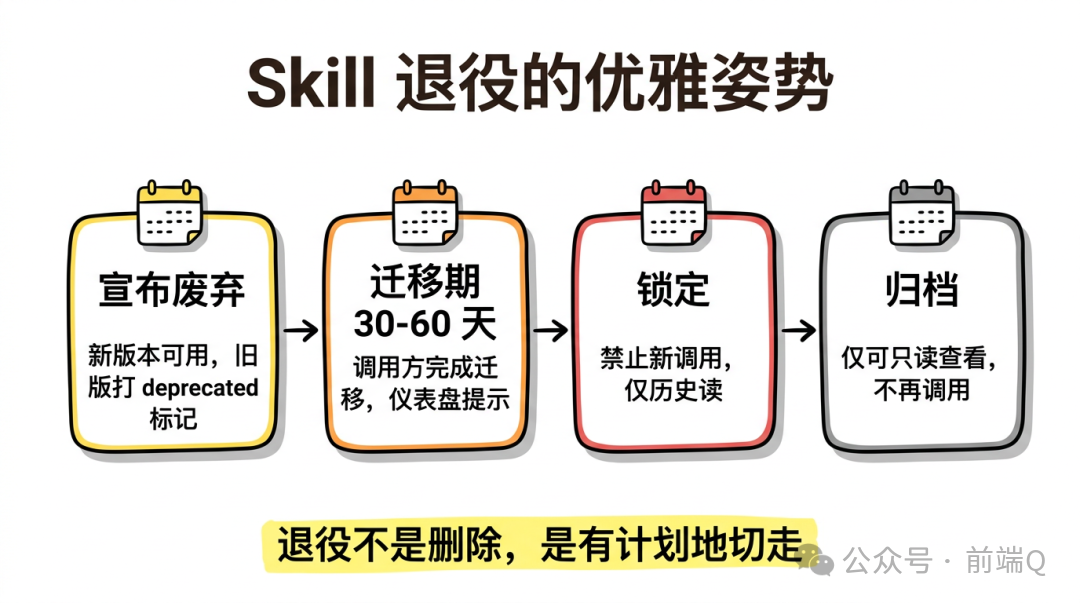
合格的废弃必须分四步走:
第一步:标记 deprecated
修改 frontmatter:
deprecated 之后,Skill 仍然可以调用,但 Hub 会在调用时打印警告。
第二步:通知所有调用方
不要假设大家会主动看变更日志。
第三步:迁移期
通常给 30 天迁移期。
期间:
第四步:retired 与归档
迁移期满后:
retired 不等于删除,元数据仍保留在 Hub 里,作为历史记录。
某种意义上,retired 的 Skill 就是组织 AI 系统的"考古档案",未来如果有人想看"我们曾经怎么处理这类问题",还能查到。
一个生命周期治理仪表板长什么样
整合上面所有阶段,企业 Skill Hub 应该有一个"生命周期仪表板":
这种仪表板的好处:
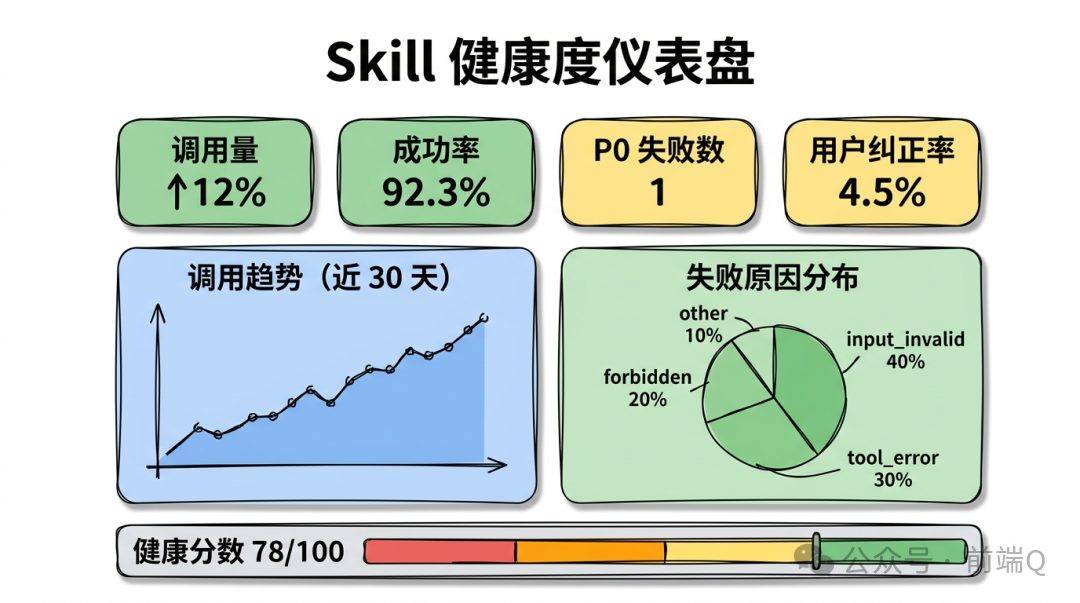
仪表板不是"装饰",而是把"长期治理"这件事从老板嘴上的口号,变成每周可以跟进的 backlog。这是 Hub 真正能跑很久的关键。
真实场景:被遗忘的"实验性 Skill"
讲一个真实例子。
某团队 1 月份创建了一个 Skill db-migrate-advisor,标记为 experimental,主要用于辅助数据库迁移。
写完之后没人继续推进,也没升档。但这个 Skill 仍然在 Hub 里能被调用。
到了 4 月份,公司一次大型数据迁移,有人发现 Hub 里有这个 Skill,就调用了。
结果:Skill 写的还是 1 月份的逻辑,期间数据库版本升级了,部分语法已经过时。Skill 引导工程师用了已废弃的迁移方式,差点出事。
复盘后做了三件事:
给 experimental 加超期检查:超过 60 天未升档自动告警
给 deprecated 加调用量监控:仍有调用且超期未迁移自动告警
给 stable 加漂移监控:指标趋势明显恶化自动告警
这就是生命周期治理的真实价值。它不是"流程多",它是"让东西不会被遗忘"。
我的判断
我现在越来越觉得,Skill Hub 不是一个"仓库",而是一个 生态。
仓库只关心"东西放进来了没"。
生态关心的是:
把 Skill Hub 当生态来做,企业 AI 能力才能真正持续演进。
下一篇我会进入更具体的实战层面:企业级 Skill Hub 的架构设计。前面我们讲的所有规范、门禁、生命周期,背后都需要一套架构来承载。这套架构怎么设计、怎么取舍、跟什么系统对接,下一篇说清楚。